「機器學習相關實驗」管理的想法,是去年在 Apple 實習萌芽的,那時覺得公司內部相關工具 overhead 不少,doc 也不全,加上界面太好看(?),就沒有使用,而是用相當土炮的方法 (自己存數據到檔案裡以及一些工人智慧)來做實驗彙整。最近手上 project 要跑的實驗量已經大到這種管理方式會很吃力 (500 exp up),便開始找尋現成的工具,而 Comet.ml (以下簡稱 Comet ) 在眾多框架之中脫穎而出,我想之後我寫的扣要 import tensorboard 的機會微乎其微了(吧) ,而這麼好用的工具網路上卻沒什麼中文的介紹文,於是來跟大家分享 😎
文章同步刊登於 Medium
Prior
這篇文章可能對什麼樣的人有幫助
- 進行機器學習及資料科學相關研究,每秒幾萬個實驗上下,想試試新工具
- 與他人合作,需要分享實驗數據,不想處理權限管理等麻煩事
- 不想在自己本機開 DB port ,有 security 疑慮
單純想跟別人不一樣
Comet 提供了什麼
- 資料庫檢索功能 (如欄位 filtering,數值欄位排序…)
- 官方統一平台的實驗數據共享
- 更多功能,像是 corpus 及 code 的版本控制、reproducibility 、hyper-parameter search,但我暫時沒用到)
Comet 沒有 提供什麼
- 如 AWS 或 Google Cloud 的運算資源(它只提供儲存及處理實驗數據相關的服務)
- 實驗數據導出(目前僅能導出 圖表的 SVG 或 jpeg)
- 客製化的實驗比較 (後面會再詳述)
學生族群最在意的錢錢
Comet 提供了三種不同的收費方案,免費的 Public Workspace 方案跟 GitHub 一樣,可以開無限的 public workspace,同時容許 10 個實驗跟 Comet 互動,但如果你在學校機構做事的話 (aka 擁有 edu 的 email),可以免費享有最高級的 Teams Workspace 方案 (一個月價值 179 USD) ,可以開無限的 private workspace,容許 500 個實驗同時跟 Comet 互動。(還不心動嗎嗎嗎~
資料庫檢索功能 & Python API
在用 Comet 前的實驗紀錄,我是用 Notion 維護一張表格如以下 (話說 Notion 也是個極度好用的工具)
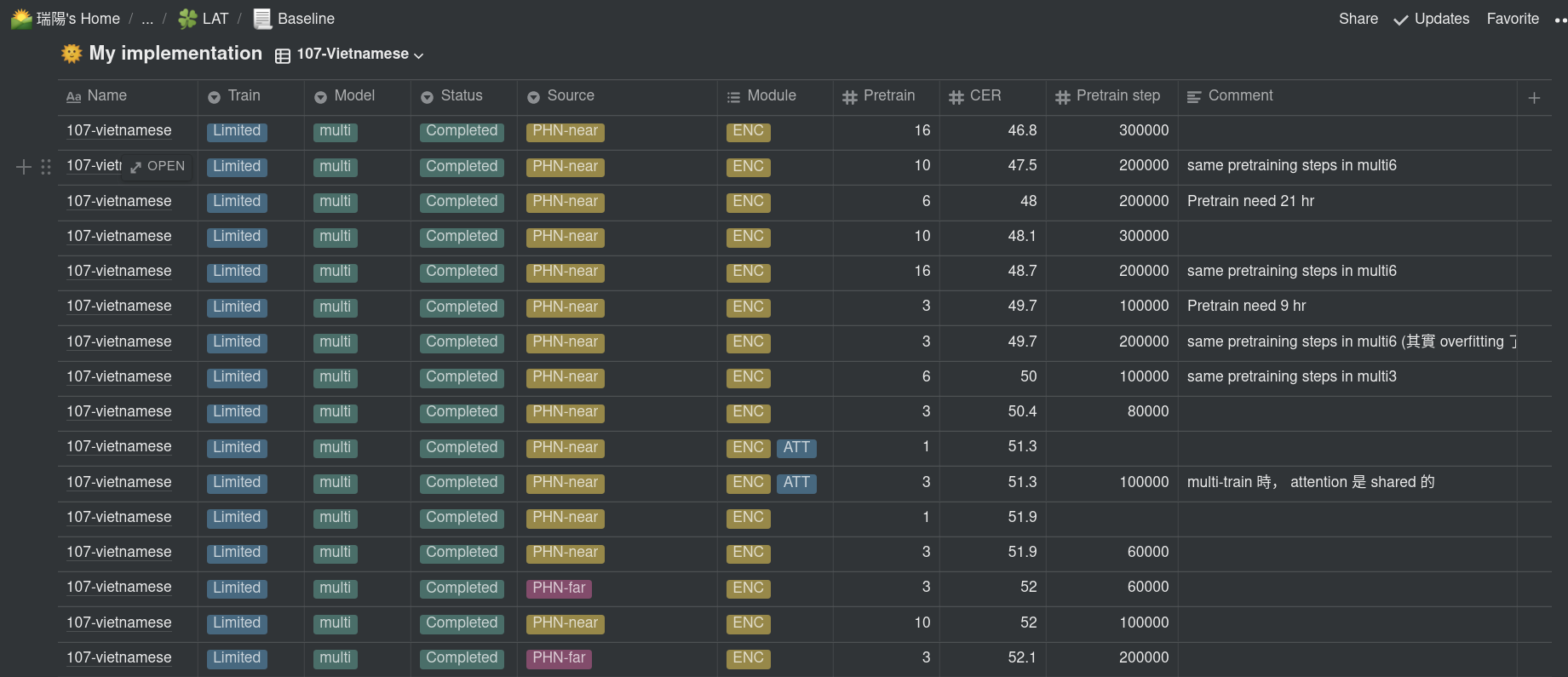
- 透由 filter ,查看不同 View 實驗結果
- 為不同筆實驗 (如不同的模型設置、不同(預)訓練資料、不同演算法 …etc) 增添 tag ,方便後續管理及查找比較
- 因為我們實驗室有共用的運算資源 ( 以下簡稱戰艦 ),可以同時平行跑不少實驗,但目前有些功能尚待補齊 (如 job execution 的 dependency ),而且畢竟學校不比業界,機器偶爾也會 shutdown ,所以我需要去定期人工 sync 目前有哪些實驗跑到哪個階段 ,決定過來需要放哪些實驗下去跑,便需要紀錄實驗的 status (就我的 project 而言,分為 null/ pretrain/ train/ decode/ complete)
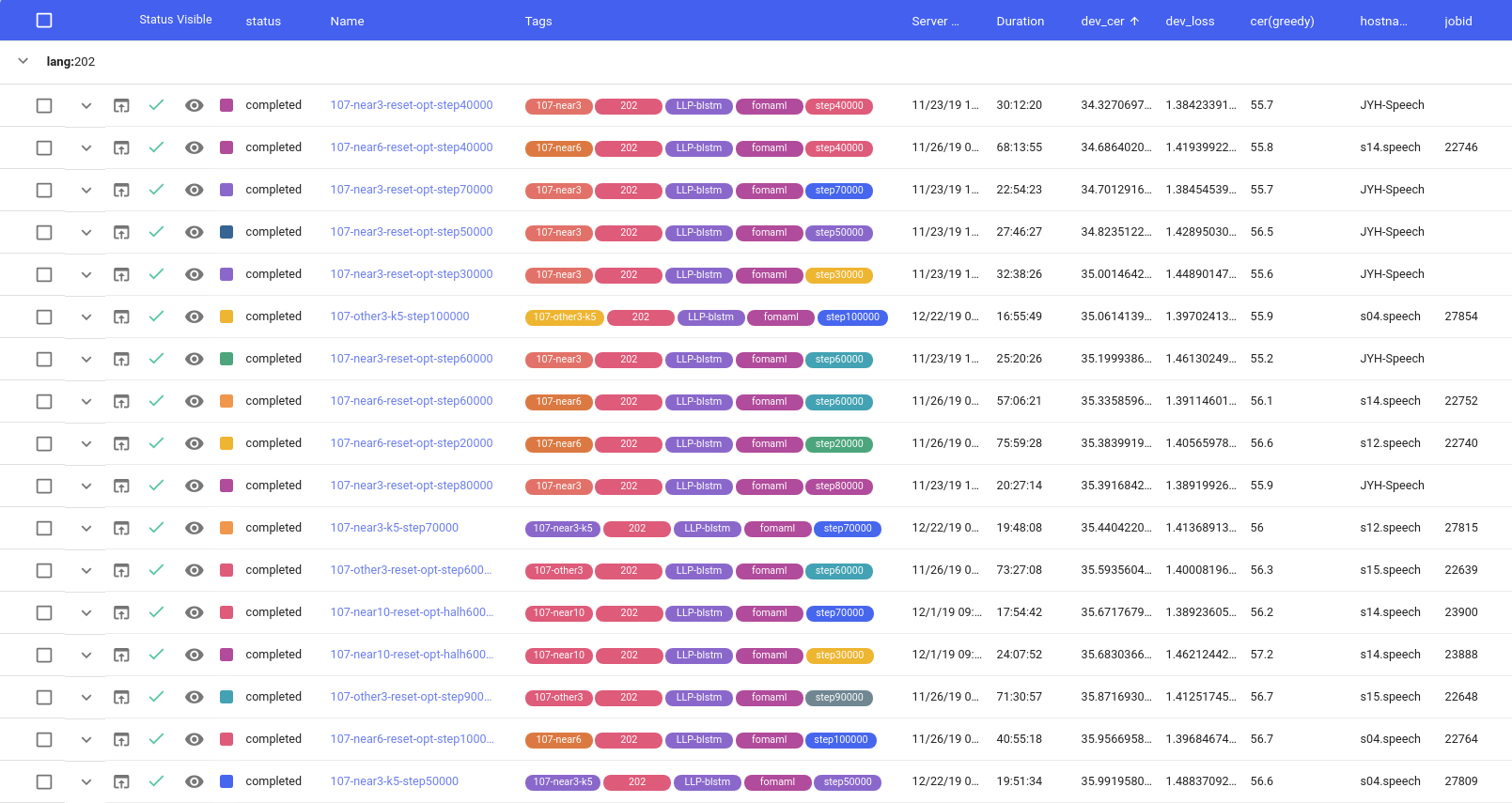
聽起來還不賴,但是有了 Comet 之後,我有了另外一張表,而且多虧官方提供的 API ,這一切能全部自動化,而且使用方式跟 Tensorboard 非常類似 (只需在原先的程式裡如 Tensorboard 般 add_scalar, add_image… log 想加的資訊即可,完全無痛轉換) 。而且 Comet 也會紀錄實驗的狀態 (running, completed, interrupted),方便掌握實驗進度,以及是否需要重跑等等。 簡言之,相較於 Tensorboard 提供的陽春 regular expression filter runs 功能,Comet 不僅在視覺的呈現讓人一目了然,在管理實驗上也更加方便。
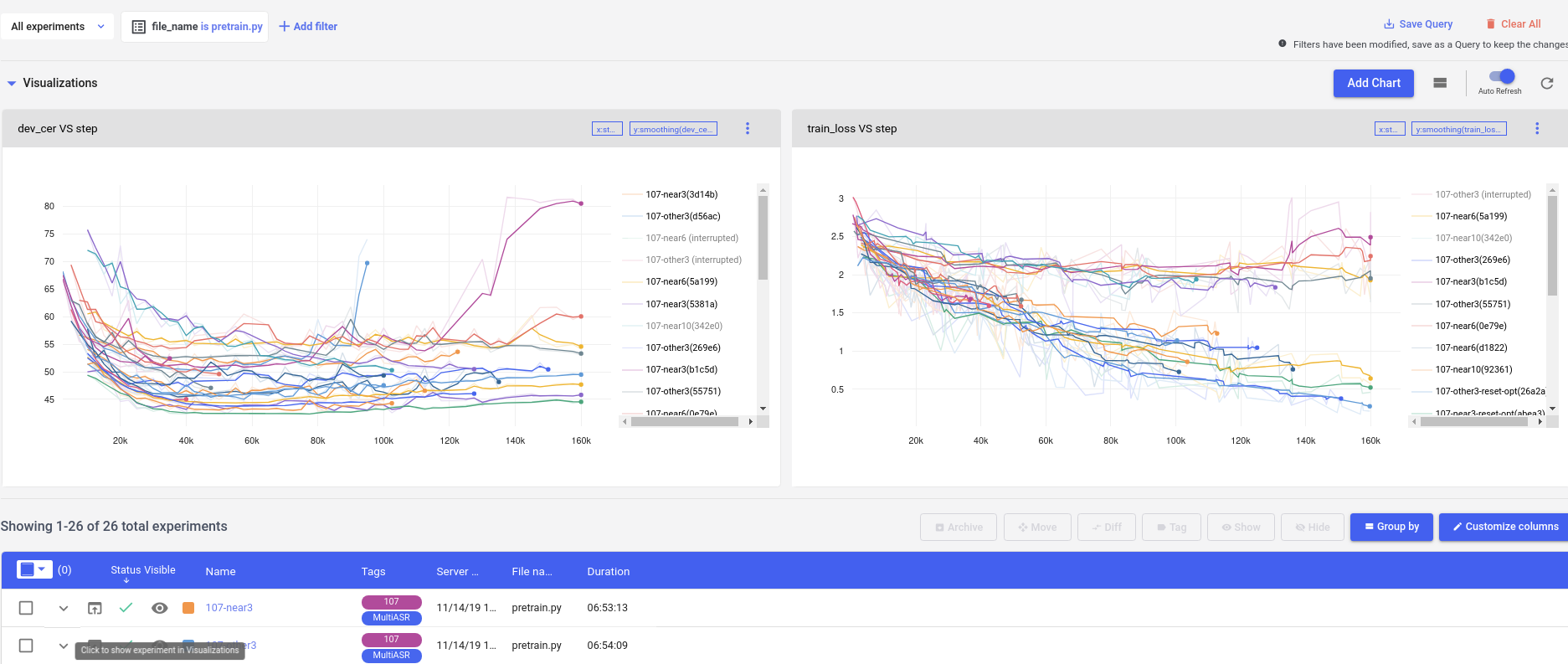
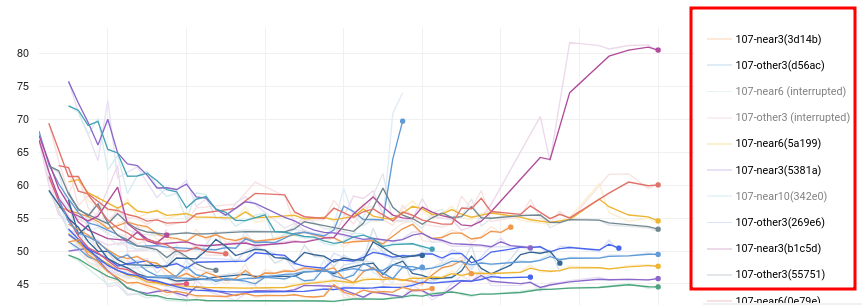
官方統一平台的實驗數據共享
我的專題研究是兩個人一起進行的,以往如果想要共享實驗數據,又不想把本機或戰艦的帳密讓隊友知道的話,大概就是公開 Tensorboard 的 port 讓隊友可以連,這麼做沒有不好,但 Tensorboard 在實驗數據增加的情況下,載入的速度會慢到無法忍受 (torch.utils 的 tensorboard 的話,我想 30 個 runs 你就知道厲害了…)。另外,Comet 預設會 log hostname 及 username,也方便合作者知道要拿數據該從哪裡拿 ( 其實 Comet 可以存 checkpoint 到官方平台,不過因為卡外網頻寬,所以我選擇把要存的資料留在電腦上)。
而為什麼選用官方平台呢?之前也 survey 了sacred,一樣提供資料庫系的管理功能 (這目前是 ML 實驗管理工具標配),但因為要在自己桌機上另外開 DB port,雖然是網管但我跟網路也沒到很熟(?),使用之前也必須先考慮一些 security 問題,當初急著找工具就先找類似 Comet 一樣有官方平台的工具,當然 tradeoff 就是你的 code 或數據會讓該服務讀取,有機密疑慮的 project 就不適合 (但反正我 code 都 push 到 GitHub 了…😅),anyway 之後找機會也會來玩玩 sacred。
還少了什麼呢?
以下會提到目前我覺得不太方便的地方。
雖然 Comet 可以下 query 檢索我們要的實驗,把實驗的圖表畫在一起比較,但可惜的是只能導出成影像檔,不能 dump 對應的 log 出來 ,所以如果要放在正式的文章中,還是得自己抓數據出來重畫圖。
另一點則是他圖的 label 只支援 exp name/ key,不支援其他欄位。這有什麼差呢?key 通常是他算的一個 hash 看不懂故不考慮,name 的話則是在 comet 中可以 set 的一個 metadata,但考慮以下情況,假設你有 A, B, C 三個 category ,每個 category 不同實驗會有不同的 attribute (e.g a1, a2, b1,…) ,常常我們會固定 B,C 的屬性,觀察不同 a attribute 的影響,或固定 A, C,看 b 的影響…等等,如果要讓 label 唯一的話,辦法就是把所有 attribute cascade 在一起 (就像 Tensorboard 的 runs 一樣…) ,不是很 elegant ,但不這麼做就會有 label conflict 的問題。如下圖,因為我不想讓 exp name 太長,便拿一個 category 來命名,便發生 conflict,只能依 key 去區分實驗,但就要一直滾上滾下比對…。