在這一講中,要介紹的是 RL 中的 supervised 系方法 - Imitation Learning。想法是收集 expert (or say, “ground-truth” agent) 與 environment 互動的$(s,a)$ pairs 去 train 我們的 agent/actor。那麼該如何利用這些 $(s,a)$ pair 呢?
Behavior cloning
Make training set $D = \lbrace \mathcal{X}, \mathcal{Y} \rbrace$ be $\lbrace (s_1,\hat{a_1}),\cdots,(s_N,\hat{a_N}) \rbrace$
Issue#1 - Distribution Drift
Unlike conventional supervised learning setting,在 RL 中每個 training data 並非是 i.i.d (白話來說,在某個時間點所作的決策,會影響到後續所收到的 sample),也因此,儘管在每個 step 都只犯了小小錯誤,這些錯誤卻會 accumulate 。
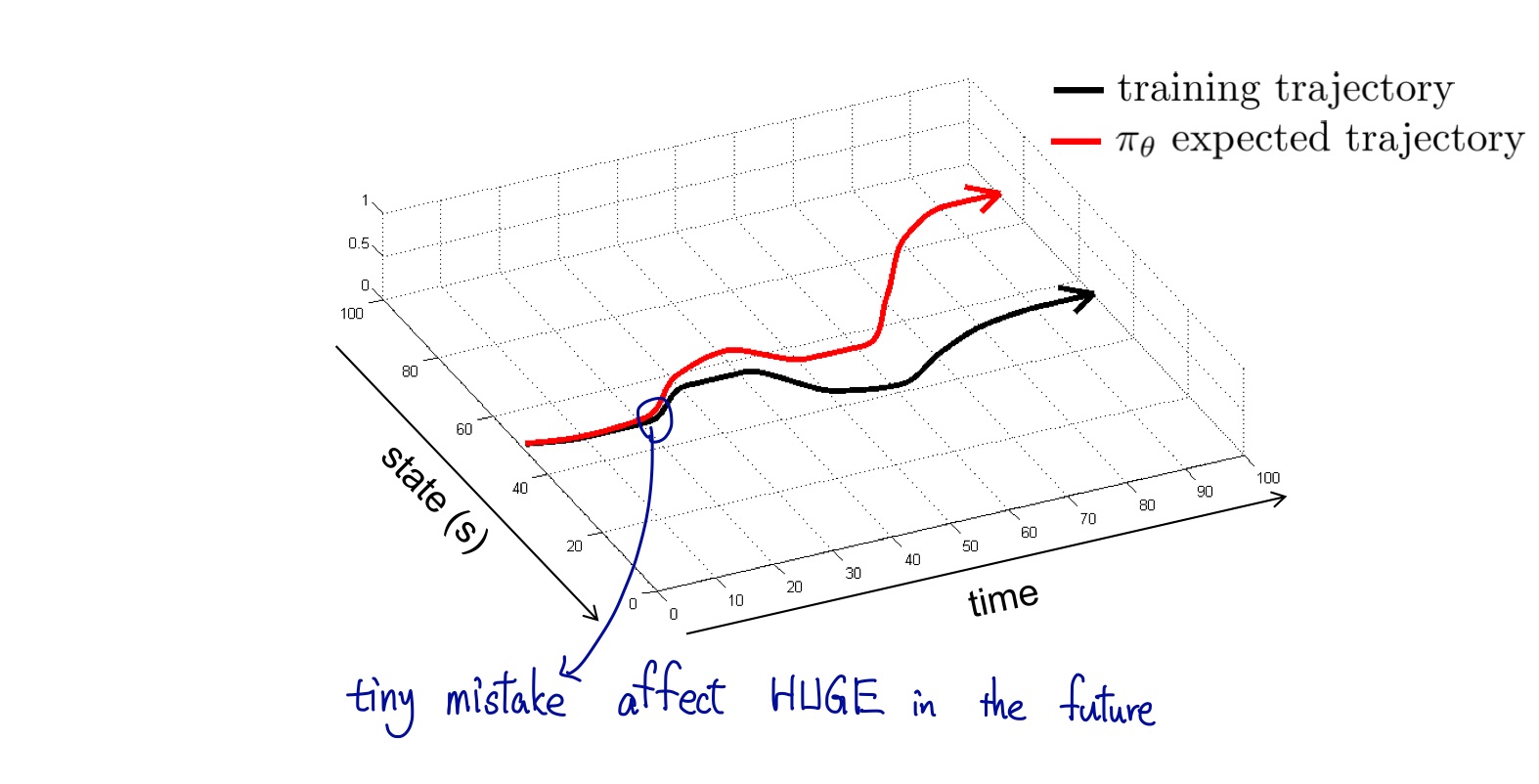
$$ p_D(s_t) \not = p_\pi(s_t) $$
Error Analysis
Assume $\pi(a\not = \hat{a}|s) \leq \epsilon$, then $\forall s , \text{in one episode (length T)}$
$$ \mathbb{E}\lbrack \sum_t 1\!\!1[a_t \not = \hat{a_t}]\rbrack \leq \epsilon T + (1-\epsilon)[\epsilon(T-1)+(1-\epsilon)\cdots] \color{red}{\Rightarrow \mathcal{O}(\epsilon T^2)} $$
Solution#1 DAgger - Dataset Aggregation
In brief, colect training data from $p_\pi(s_t)$ instead of $p_D(s_t)$,就是 run 現在的 policy 去收集 data ,再由 human expert 去 label,最後再將其與原先的 training set 聯集起來,再重複此步驟。
Remark:
- 就像是讓學生回去寫作業,遇到不會的再拿來學校問老師。\
- 中間牽涉到 human labelling 的 interaction,為效率的 bottleneck
Solution#2 Make model equipped with some property
- Non-Markovian: 考慮到 data 間 sequential 的關係,以 recurrent-type 的 model 作為 agent model (e.g RNN)。
- Multimodal: Given same state, 人類可能會做出不同決定
- Mixture Model: 最後 output 的並非一個 action $a$,而是一個 distribution。簡單來說,以 GMM 來 model 該 distribution,讓 model output GMM 所需的參數。
- Latent Variable Models: 待補
Issue#2 - Limited Capacity
許多 expert 無意義的習慣(?) 也會被 model 學進去, 若 learning capacity 是 limited 的話,重要的 behavior 反而沒學到 (因 label 並沒有 split 哪些不同的 sub-behavior 是沒關係,哪些又有關係)
Remark: 如果對 domain 有些了解,可以利用人工 augment noise 進去,再用 adversarial 去 alleviate 這個 issue。不過更根本的問題在於 factorize 這件事現在的方法都還不是做的 generally 非常好
Inverse Reinforcement Learning
In brief, 藉由 $(s,a)$ pairs 去 model 可能的 reward function $R$,而有了 $R$ 後,便可套用前面 4 講提到的 RL algorithm 去 update $\pi$。
Remark: Simple reward function can cause complex policy,算是有點找出源頭的味道。

With constraint $\sum r(\hat{\tau}) \geq \sum r(\tau)$
Remark: 這裡的 insight 在於跟 GAN 的類比。
Some Thoughts
- 很多時候不知道該如何訂做了哪個 action ,該給多少 reward (usually in complex task),下一講則會介紹如何處理 Sparse reward 的問題。
- Provide 較為明顯的 training signal,讓機器在學習的過程中,更善加利用人類發現的結果,站在巨人的肩膀上。
- Ditribution drift 的問題,跟之前 Off-policy 想處理的問題類似,可否利用 Importance Sampling 去改進?
Reference
- [CS294-Lec2] (http://rail.eecs.berkeley.edu/deeprlcourse/static/slides/lec-2.pdf)
- [NTU-MLDS] (http://speech.ee.ntu.edu.tw/~tlkagk/courses/MLDS_2018/Lecture/IRL%20(v2).pdf)