上一講提到了利用 nonlinear transform 來處理 data 並不 linear separable 的情形,讓 ML model 具備了更強的 fitting 能力,但在這麼做的同時,也提高了 hypothesis set 的 VC dimension,使得 model 的 complexity 增加,變得不容易 generalizaion ,而這也是這一講要探討的 overfitting 。
比喻
如果將 overfitting 比喻成車禍的話,用過於複雜的 model 就像車速過快一樣,而 noisy 的 data 則如同不平的路面,有限的 data 則是我們所觀察到的 partial 視野。 那更細部來看, noise 及 limited dataset size 是怎麼造成 overfitting 的呢?
實驗
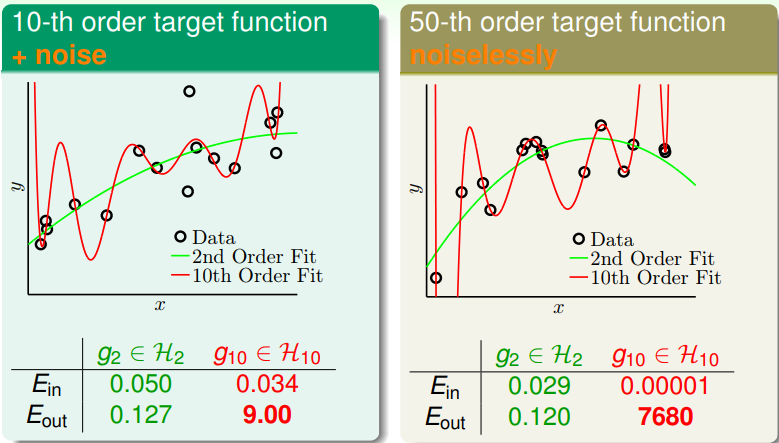
上面的圖呈現了兩個實驗,並介紹了一個較不直覺的發現。
我們分別拿 2 次及 10 次的 polynomial model 去 fit 有 noise 的 10 次 polynomial 及 noiseless 的 50 次 polynomial,發現 10 次的 function 都表現的比較差。對於第一個 實驗還好理解,過於複雜的 model 把雜訊也 fit 進去,結果理所當然比較差;然而第二個實 驗結果就比較反直覺一點,對於 noiseless 的複雜 model ,用高次的 model 結果反而會 比較差?
Explanation
事實上,對 complexity 小的 model 而言,要 fit 的 target 如果過於複雜,使得其不 論怎麼 optimize 都無法 fit 時,這中間的 gap (i.e target complexity) 之作用就如 同 noise 一樣 (but it's deterministic)。
Complete Analysis
以下兩張圖分別以 Noise 的大小及 Target function 作為變因,觀察 model complexity 與 overfitting 之間的關係。
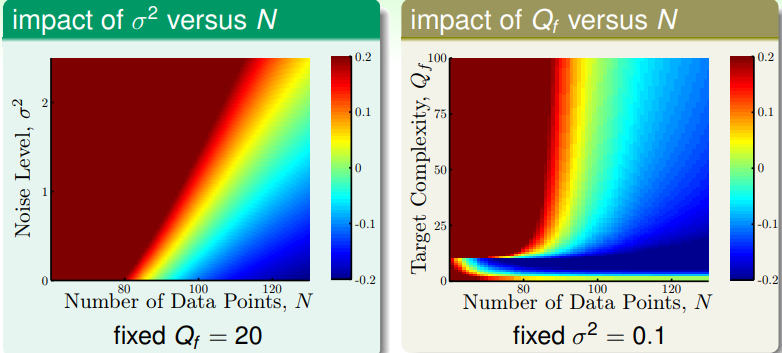
-
Noise 為變因的實驗:隨著 noise 的增強,複雜的 model 需要更多 data 才能避免 overfiting , they are more sensitive to noise 。
-
Target Complexity 為變因的實驗:大部分走勢與上個實驗相同,在左下角那裡有塊變化 劇烈的區域 (大概落在高次 model 的 VC dimension ),若 target complexity 在那個 值以下,多給幾個 data point 的影響很大 (which is also inuitive) 。
Howt to overcome overfitting
- Start from simple model: 一開始不要用過複雜的 model (一開始先慢慢開)
- Data cleaning/pruning: 消弭 noise (讓路變平)
- Data hinting: 做 Data Augumentation,利用現有的道路資訊,去推出更多相關的 info , Need more domain knowledge
- Regularization: 煞車 (more on next lecture)
- Validation: 選出 generalize 最好的 model (carefully monitor)