ASR 做的其實就是以下這件事,
$$ \Pr(\text{words|sounds}) = \frac{\Pr(\text{sounds|words})}{\Pr(\text{sounds})} $$
當中我們視 $\Pr(\text{sounds})$ 為 uniform distribution ,不管它。
\
$\Pr(\text{words})$ 由 Language Model 負責,評估產生的
transcription 之合理性 (e.g 電腦聽聲音 vs 點老天呻吟)\
$\Pr(\text{sounds|words})$ 則是 Acoustic Model, 也就是前一講中用 Viterbi 所算的 Likelihood 。
Basic Unit Choice
前面提到,我們利用發音規則所建的 lexical model 去串接 phoneme 的 HMM model 形成 word 的 HMM model , 不同word 的相同 phoneme 會使用同一個 model 。但是 phoneme 彼此間亦會有所影響 ($\rightarrow$ coarticalution ),所以會造成 mixing…,但是選擇對 word 建 HMM model 又會面臨對應到每個 model 的 data 數不夠的問題,參數太多又容易 overfitting ,也因此目前最常使用的 tri-phone 應運而生。
$$ d-a+g, \quad d-a+f $$
上圖中的 ‘a’ 對應到不同的 tri-phone ,但 tri-phone 不是去串接這三個 phone 的 model ,而是對有不同 context 的相同 phone 去訓練不同的 model 。
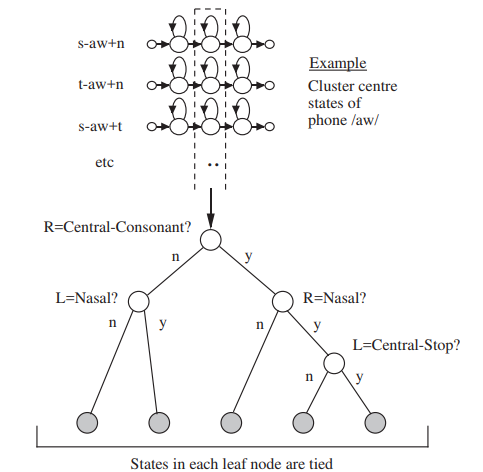
但這麼一來,會遇到把 word 當 basic unit 使得每個 unit sample 都不夠多的問題 (雖然沒那麼嚴重),因此,我們想對 發音類似的那些 tri-phone 中的某些 state 做 weight sharing (e.g 上例中,prefix 相同,第一個和第二個 state 或許就可以 share)
可以用 data-driven 的方法 automatically 決定如何 share (e.g Hierarchical Clustering 去 merge state emission probability 相近的那些),但現行最常用的還是比 較 engineering 的方法 - CART (Clasification and Regression Tree) 。
利用語音學的語法規則,設計在這棵 decision tree 上 branching 的 criteria ,分到相同 branch 下面的 state 們就可以共用 (我們把最後被 cluster 在一塊的那些稱作 senone )
MISC
- 衡量 performace 的好壞常使用 WER (Word Error Rate),會需要對辨識出來的結果做 realign 再去跟 ground truth 算這個值 (by DP)。
- 增加 Sampling Rate 到 16 kHz 可以降低 WER,再高就沒什麼幫助了
- 考慮 MFCC 的 $\Delta$ 和 $\Delta \Delta$ feature 可以降低 WER (也是最常見的 39-dim MFCC)