隨著變成菸酒生的日子逐漸逼近,最近開始重追尤達大師數位語音的連載,希望在進 Speech Lab 之前,將這些知識掌握地更加純熟,這個系列主要會雜揉以前在台大所修的 數位語音處理概論 以及在 KTH 所修的 Speech and Speaker Recognition 之相關內容。
Introduction
語音辨識,顧名思義,是想把一段在物理世界中存在的,有資訊的聲音訊號,儘量在不喪失太多資訊下,轉成文字 (symbol sequence)。這裡不說成是單單 speech to text 是因為人類在溝通的時候,除了說話的內容外,語調的變化,肢體動作,面部表情等等,無一不是在傳達資訊,但這些並不是 ASR 所要處理的部份。從早年 1950 Bell Lab 所做的僅有 10 digits, 1 speaker 的辨識到現在的語音助理們所具備的辨識功能(雖然語意理解上有障礙,但辨識效果我是覺得真的挺好的),中間的關鍵及發展有哪些呢?就讓我們繼續看下去~
分類
- Speaking Mode: isolated word vs continuous speech (後者其實就是由很多辨識前者的模型所構成,再利用 Language Model 來選出最可能的 sentence )
- Speaking style: read vs spontaneous (後者會有冗言贅字,另外,read 相當於是先 text to speech 再 speech to text,像是是高興還是生氣地說出這段話,原先的 text 當中就會有說明, 經過 ASR 後的資訊 loss 比較少)
- Specific speaker vs general speaker (不同的人講話本來就不同,常用的方法是做 speaker adaptation)
-
of vocab: 牽涉到 unit model 的選擇 (word vs phoneme)
- Robustness: 對噪音的耐受能力 (但不僅限於背景 noise ,像是不同的收音裝置, speaker 與其的距離等等…都是)
基本架構
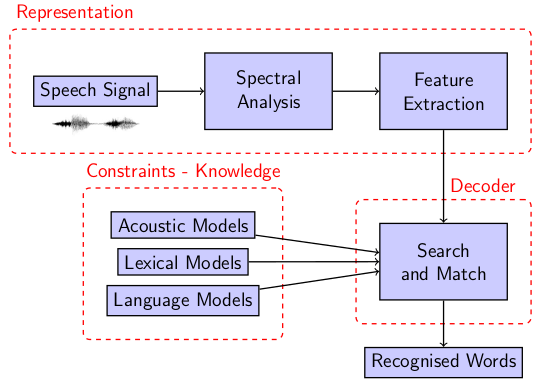
(From KTH DT2119)
之後的幾講會圍繞著這張架構圖展開。
comments powered by Disqus